常用数据采集手段
人气:0常用数据采集手段
埋点——用户行为数据采集
- 埋点技术:收集用户在产品上面的点击和浏览情况,用于运营分析。隐性的信息收集。
- 埋点:在正常的业务逻辑中,嵌入数据采集的代码。
- 弊端:可能会被用户认为侵犯隐私。
- 埋点优势:数据是手动编码产生的,易于收集,灵活性大,扩展性强。
- 埋点劣势:必须十分清楚目标,需要什么样的数据必须提前确定;容易发生漏埋现象;产品迭代过程中 ,忽略了埋点逻辑的更改。
埋点方式
- 全埋点/无埋点:“全部采集,按需选取”;在产品中嵌入SDK,做统一埋点,一般用于采集APP的用户行为。(百度统计——基于无埋点技术的第三方统计工具)
- 可视化埋点:在全埋点部署成功、可以获得全量数据的基础上,以可视化的方式,在对应页面上定义想要的页面数据,或者控制数据。
- 代码埋点:前端代码埋点和后端代码埋点。更适合精细化分析的场景,采集各种细粒度数据。(适合技术人员,前两种适合市场和运营人员)
埋点采集数据的过程
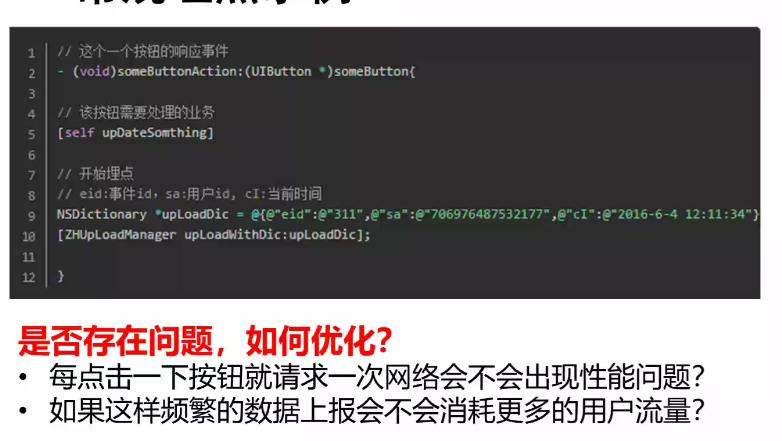
常规埋点示例
埋点方案应具备四个要素
- 确认事件与变量:事件指产品中的操作,变量指描述事件的属性。按照产品流程来设计关键事件。
- 明确事件的触发时机:不同触发时机代表不同的数据统计口径,要尽量选择最贴近业务的统计口径,然后再与开发沟通。
- 规范命名:对事件进行规范统一的命名,有助于提高数据的实用性及数据管理效率。
- 明确优先级:在设计埋点方案时,一定要对埋点事件有明确的优先级排布。
常用埋点APP数据分析工具
- Growinglo
- 百度移动统计
- 神策分析
- 腾讯移动分析
- 谷歌GA
ETL——系统业务数据整合
- ETL的概念:用来描述将数据从来源端经过抽取(extract)、(清洗)转换(transform——按照数据规则进行清洗转换,花费时间最长一般是整个ETL的2/3)、加载(load——加载至数据仓库或进行可视化展示)至目的端的过程。
- 常用的三种实现方式----借助ETL工具、SQL方式实现、ETL工具和SQL相结合。
- ETL工具解决的问题:数据来自不同的物理主机、数据来自不同的数据库或者文件、异构数据处理等。
常用的ETL工具
- Kettle:一款国外开源的ETL工具,纯java编写,数据抽取高效稳定(数据迁移工具)。
- Apatar:开源ETL项目,模块化架构,支持所有主流数据源,提供灵活的基于GUI、服务器和嵌入式的部署选项。
- Scriptella:一个开源的ETL工具和一个脚本执行工具,支持跨数据库的ETL脚本。
- ETLAutomation:提供了一套ETL框架,重点是提供对ETL流程的支持。
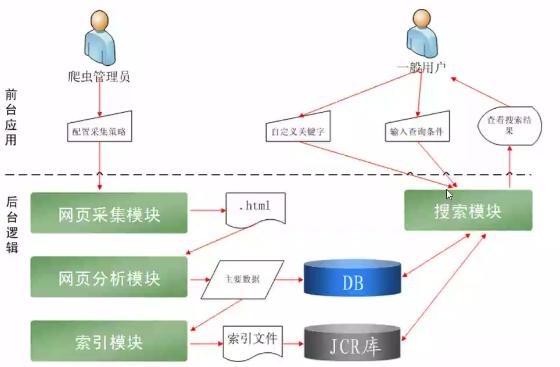
网络爬虫——互联网数据采集
网络爬虫:是一种按照一定的规则,自动抓取万维网信息(网页)的程序或者脚本。为搜索引擎从万维网上抓取网页,是搜索引擎的重要组成部分。
网络爬虫工作流程
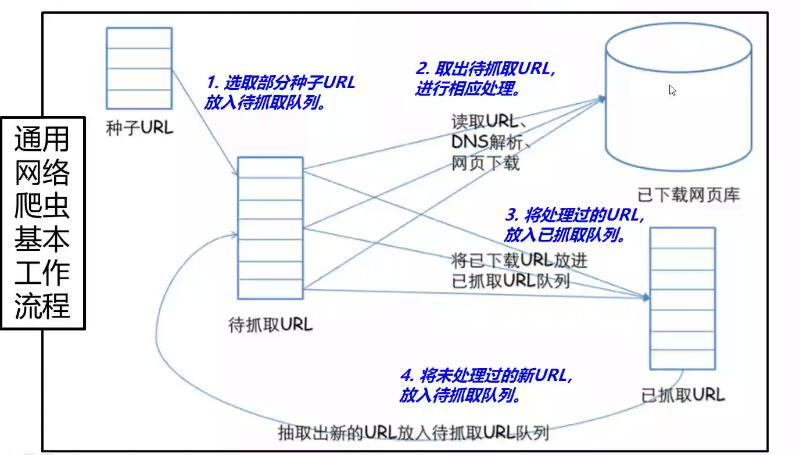
网络爬虫可分为通用网络爬虫和聚焦网络爬虫
- 通用网络爬虫基本工作流程
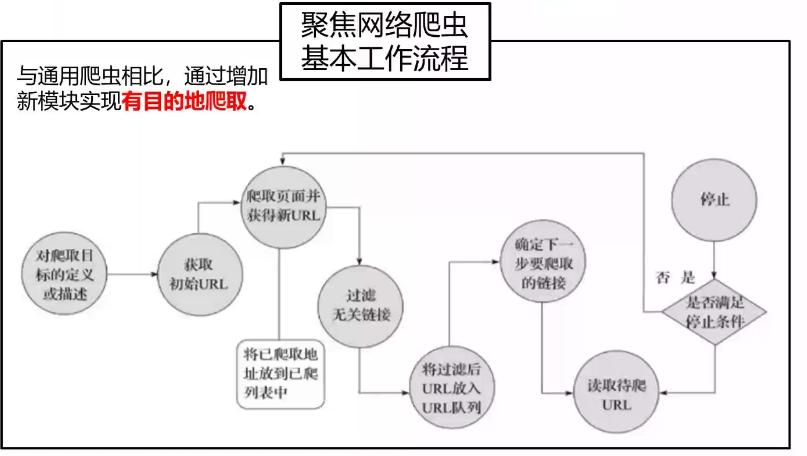
- 聚焦网络爬虫基本工作流程(通过增加新模块实现有目的的爬取)
相比通用网络爬虫新增目标定义、无关链接过滤、下一步要爬取的连接三个模块。
网络爬虫抓取策略
- 深度优先遍历策略:从起始页开始,一个个链接跟踪下去。
- 宽度优先遍历策略:抓取当前网页中链接的所有网页,再从待抓取队列中选取下一个URL。
- 反向连接数策略:反向链接数是指一个网页被其他网页链接指向的数量。使用这个指标评价网页的重要程度,从而决定抓取先后顺序。
- ** 基于优先级计算的策略**:针对待抓取网页计算优先级值,通过排序来确定抓取顺序。
- 大站优先策略:对于待抓取队列中的所有网页,根据所属的网站进行分类,对于待下载页面数多的网站优先下载。
网络爬虫定期更新策略
- 历时参考策略:在网页的的历时更新数据基础上,利用建模等手段,预测网页下一次更新的时间,确定爬取周期。
- 用户体验策略:依据网页多个历史版本的内容更新,搜索质量影响、用户体验等信息,来确定爬取周期。
- 聚类分析策略:首先对海量的网页进行聚类分析,每个类中的网页一般有类似的更新频率。通过抽样计算,确定针对每个聚类的爬取频率。
Apache Flume——日志数据采集
Apache Kafka——数据分发中间件
其他
加载全部内容